https://programmerk.tistory.com/110
Improving Language Understanding by Generative Pre-Training 리뷰
배경 : 기존 지도학습 방식은 라벨링, 어노테이션등 노동력이 필요하고, 이에 따른 적용 한계가 존재한다. 이러한 한계점 (시간적, 비용적) 극복하기 위하여 비지도 학습 방안을 고려하기 시작함
programmerk.tistory.com
https://programmerk.tistory.com/111
Language Models are Unsupervised Multitask Learners 리뷰
https://programmerk.tistory.com/110 Improving Language Understandingby Generative Pre-Training 리뷰배경 : 기존 지도학습 방식은 라벨링, 어노테이션등 노동력이 필요하고, 이에 따른 적용 한계가 존재한다. 이러한 한
programmerk.tistory.com
배경
이전까지 NLP는 특정 분야별 구조를 설계하고, 지도학습을 수행( task-specific )하였지만 최근에는 비지도 학습의 사전학습 모델( task-agnostic )과 파인튜닝을 통해 독해, 질의응답등 다양한 분야에서 상당히 발전되었다. 또한 가장 최근에는 대규모 데이터를 통해 파인튜닝 단계가 필요하지 않을 수 있다고 제시.
소개
이전 GPT 2에서 모델의 크기 (파라미터) 가 커질 수록 성능이 향상된다는 점을 검증하여 다양한 크기 모델을 만들었고, 또한 이전에 zero shot과 one-shot, few-shot을 비교하여 성능을 측정하였다. 성능을 측정한 결과 one-shot or few-shot 의 경우 zero-shot 에비해 성능일 훨씬 좋아지는것을 확인할 수 있엇고, 모델 크기가 클 수록 few-shot의 성능이 더 좋아지는것을 알 수 있엇다.

Approach
- 기존 GPT2 모델의 구조와 유사함
- 파라미터 증가
- 데이터 셋 증가
- 학습 시간 증가
- one-shot, few-shot 적용
- Few shot
모델에게 보통 10~100개의 문제와 답을 쌍으로 묶어 context 로 제공, 파인 튜닝없이 해당 context를 참고하여 문제를 해결함,
finetuning에 비해 성능은 낮음
- One shot
Few-shot 과 원리는 같으나 1개의 예시만 제공
- Zero shot
예시를 제공 하지않음
Model and Architectures
GPT-2와 동일한 모델 구조, 유사한 설정 사용
단) 일부 Sparse Attention 을 일부 레이어에 사용하여 메모리 연산량 줄임
- Dense Attention : 모든 토큰이 서로이 정보를 전부 참고하여 계산 -> 연산량 증가
- Sparse Attention : 일부 중요한 토큰끼리 참고 ( 일정간 간격, 주변 몇개, 블록별 )
- 규모
1억 2500만 파라미터부터 1750억 파라미터(GPT-3) 까지 8개 로 사용하여 스케일링 법칙( 모델 파라미터가 클수록 성능향상 ) 확인
- 학습
파라미터가 너무 커 분산 학습 수행
- Depth 분산 : layer를 나누어 각각의 다른 GPU 가 담당하도록함
- Width 분산 : 한 층에서 가중치나 연산을 여러 GPU가 나누어 각각 일부만 계산
Training Dataset
- CommonCrawl 인터넷 데이터 수집하여 필터링
- Fuzzy deduplication : 같거나 비슷한 데이터 중복제거
- known high-quality reference corpora : webText, Books1 and Books2, 영어 wikipedia
Training Process
- 큰 모델일 수록 큰 batch size를 제공하는 데신 learning rate는 작도록 설정
- Gradient noise scale 측정하여 noise에 따른 batch size 조정
- 분산 GPU 통한 병렬 처리
- NVIDIA V100 GPU 사용
Evaluation
- few-shot : 해당 과제 훈련 데이터에서 k 개 예시 랜덤하게 뽑아 컨텍스트로 넣어줌, 각각의 예시는 줄바꿈을 통해 구분
- zero-shot : 예시를 안주고 문제를 해결, 상황에 따라 예시와 문제설명 둘다 넣기도함
- 자유롭게 답 생성 : Beam search 방식 사용
Result
1. Language Modeling, Cloze, and Completion Tasks
Language Modeling ( 다음단어 맞추기 ) : 기존 최고 성능보다 훨씬 높은 점수 기록
Cloze ( 문단의 마지막 단어를 맞측) : 이전보다 18% 성능향상, 그러나 one-shot 이 zero-shot 보다 성능 저하
Fill-in-the-blank ( 빈칸 채우기) : 기존 보다 좋지만 SOTA 보다 여전히 낮음
2. Question Answering
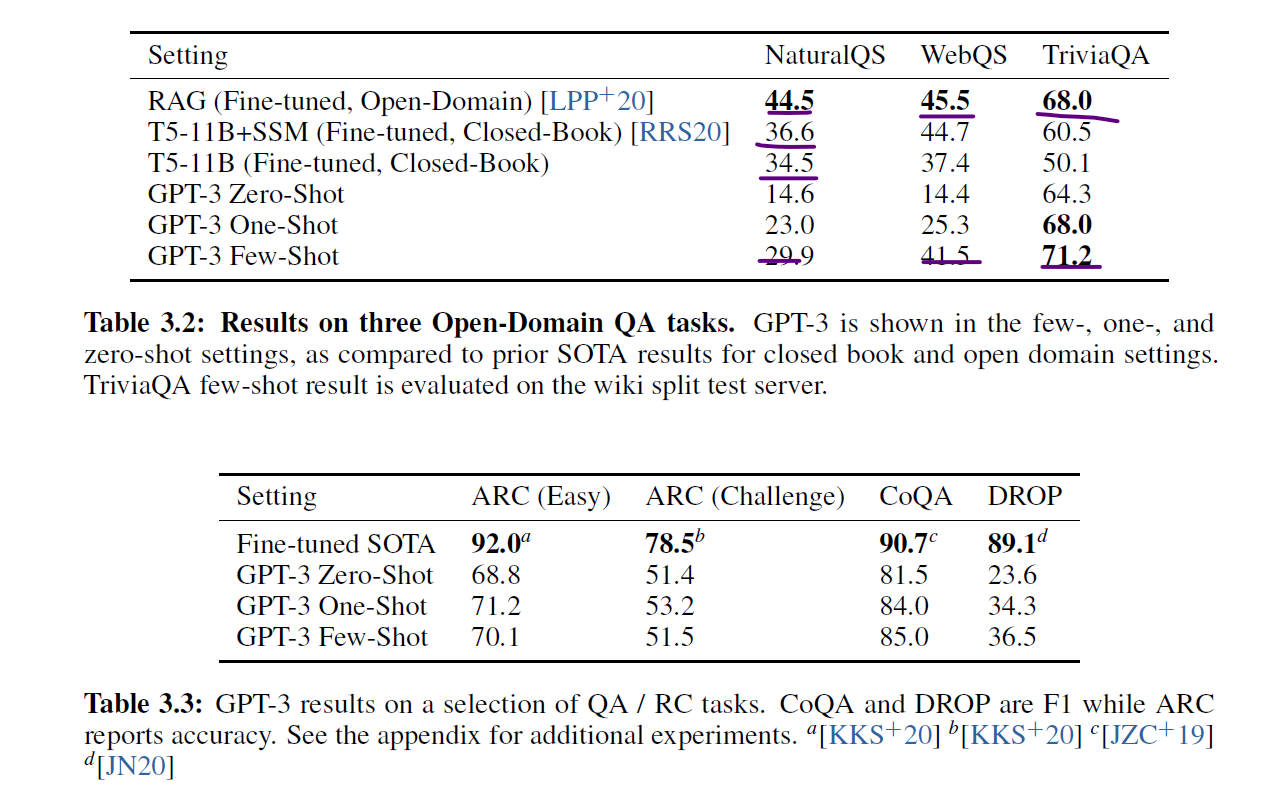
GPT-3 가 몇몇 분야에서는 SOTA와 비슷한 성능을 보이지만, 한계도 나타남
3. Traslation
수집된 데이터셋이 영어가 93%, 비영어가 7%로 구성됨
기존의 비지도 기계 번역은 각각 단일언어 데이터셋으로 사전학습하여 역번역과 결합하는 방식으로 번역수행
GPT-3는 여러 언어 혼합된 블렌드 학습
one-shot, few-shot으로 컨텍스트 추가
결과 :
one-shot : 기존 보다 성능 저하
one-shot : 기존 모델과 비슷한 수준
few-shot : 기존 최고 모델과 거의 동등 이상
특징 :
비영어를 영어로 번역할때 성능 좋음, 그 반대일 경우 성능 하락 ( 아마 BPE 때문이라고 예측 )
Limitations
- GPT-3 는 아직도 문장 생성에서 문제가 존재하긴 한다.
- 양방향 아키텍처나 denoising 같은 학습이 되지않아 잠재적으로 더 나쁜 성능을 초래한다.
- GPT-3는 모든 토큰을 똑같이 중요하게 여기며 예측하여 한계가 존재한다.
- self-supervised를 통해 예측만 가능하다
- 마지막으로, 실제 물리 경험, 지식이 없어 세상에대한 이해가 부족하다.
=> 크기만 키운 예측형 모델은 한계가 있고, 강화 학습, 인간 피드백등이 필요함
최종 이해 정리
이전 GPT2에서 모델이 커질수록 성능이 향상되는것을 확인하였고, 이를 기반으로 8가지 크기가 다른 모델을 만들어 스케일업 이론을 검증할것이다. 모델은 1억 2500파라미터 부터 1750억 파라미터 크기를 가진 다양한 8개의 모델이다. 또한 제로샷의 성능보다 원샷, 퓨샷(1~32개) 예시를 제시하는것이 더 높은 성능을 보인다는것을 알게 되었다.
모델은 기존GPT 2와 거의 유사한 방식을 사용하였고, 학습 파라미터가 많기 떄문에 깊이 방향, 넓이 방향의 병렬 학습을 수행하고, attention 매커니즘 또한 dense Attention과 Sparse attention을 교차로 넣어 사용하여 연산량을 줄였다.
데이터 셋으로는 기존과 같은 common crawl 데이터와 영문 위키디피아, books1 and book2 데이터, 기존에서 추가된 데이터등을 사용하였다
학습 프로세스에서는 모델 크게이따른 배치사이즈를 확장하였으며, 배치사이즈가 큰경우 learning rate를 낮추는 방향으로 진행하였고, noise gradient를 평가하여 batch size를 조절하도록 하였다.
모델의 평가 결과 일부 영역에서 모델의 크기가 커질수록 성능이 향상되는것을 알수있었고, one-shot leaning 만으로도 기존의 SOTA와 유사한 성능을 , few shot에서는 기존 SOTA를 뛰어넘는것을 확인 할 수 있엇다.
다반 아직도 성능적 한계가 존재하며 사후 휴먼 피드백이나 강화학습을 통해 성능을 향상시켜야할 부분이 많이 남아있다