배경 :
기존 지도학습 방식은 라벨링, 어노테이션등 노동력이 필요하고, 이에 따른 적용 한계가 존재한다. 이러한 한계점 (시간적, 비용적) 극복하기 위하여 비지도 학습 방안을 고려하기 시작함.
제시하는 방안 :
1. 비지도 학습으로 사전학습
2. 지도학습으로 파인튜닝하여 성능향상
3. Transformer 의 decoder 구조 사용
구조 :
1. Unsupervised pre-training
bookcorpus 를 사용하여 likelihood 최대화 학습

트랜스포머의 디코더만 사용 이유
> 다음 토큰을 순차적으로 예측하는 생성적 사전 학습(generative pre-training) 목적에 잘 맞기 때문입니다.
디코더는 이전 토큰들만 참고해서 다음 토큰을 예측하는 autoregressive 구조를 갖고 있습니다. 이 특성 때문에, 문맥 내에서 앞부분 토큰 정보를 활용해 자연스러운 다음 단어를 생성하는 데 강점이 있습니다.
반면, 인코더는 전체 입력 시퀀스의 정보를 동시에 처리하여 문장 전체를 이해하는 데 최적화되어 있습니다. 그래서 인코더-디코더 구조는 주로 기계 번역처럼 입력과 출력을 모두 갖는 작업에 적합합니다.
2. Supervised fine-tuning
사전 학습한 후, 파라미터를 지도 학습 방법 하여 파인 튜닝 수행
입력 x를 통해 y 예측 (3)
이를 likehood 최대화 식으로 변환하면 (4)

(a) 실제 문제 맞히기에 집중하면서,
(b) 동시에 자연어 언어 모델링도 같이 배우도록 해서,
학습 효과를 높이고 빠르게 수렴하게 만든다는 뜻입니다.

3. Task-specific input transformations
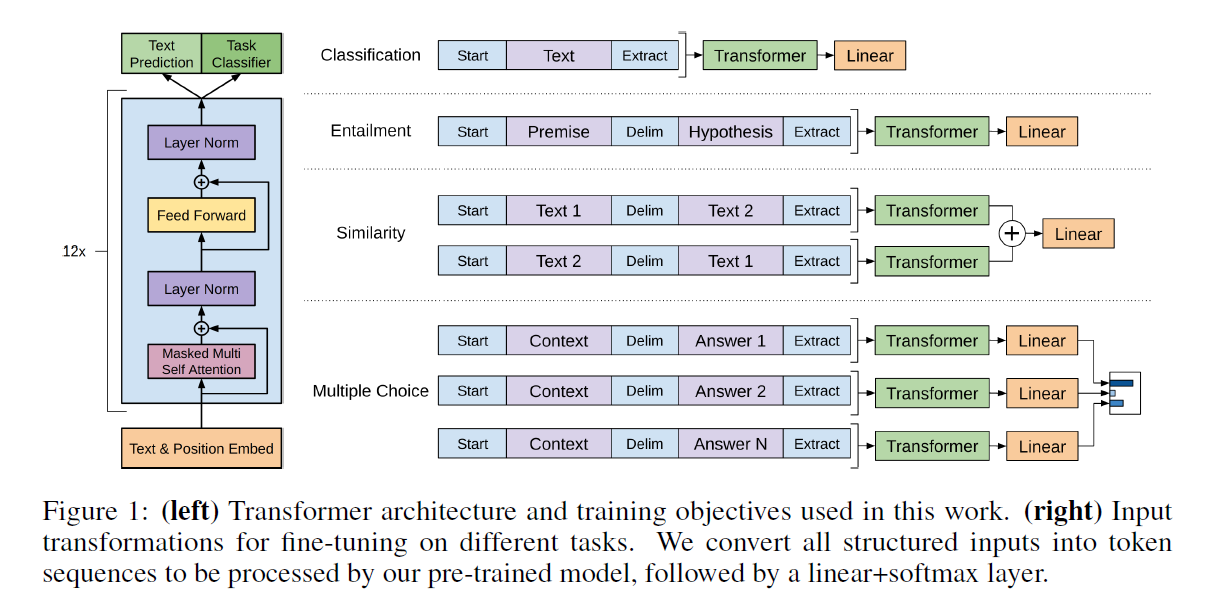
모델은 transformer decode를 12 층 layer로 만든 왼쪽과 같다.
하지만 각각 유형에 따라 데이터 셋의 토큰의 구조를 변경하여, 동일한 모델 구조로 여러 문제를 효율적으로 다루게한다.
최종 성능
네 가지 유형의 언어 이해 과제 (자연어 추론, 질문 응답, 의미적 유사도, 그리고 텍스트 분류)에 대해 평가하였다.
우리의 모델은 각 과제를 위해 특별히 설계된 아키텍처를 사용 모델들을 능가하며, 12개 과제 중 9개에서 SOTA 성능을 크게 개선하였다.
