이전 문제 :
이전 hidden state를 기반으로 다음 step의 hidden state를 순차적 생성 특성 인한 병렬 처리 불가
(기존에도 순환 구조에 Attention 메커니즘 사용하고는 있음.)
해결 방안 :
순환 구조를 배제하고 입력과 출력 사이 전역적 의존성을 온전히 어텐션 메커니즘에 의존하는 Transformer 제안,
셀프 어텐션 레이어 사용하여 병렬 처리 가능하도록 지원

어떻게 ?
Q : 이전 문맥을 유지하면서 병렬성을 어떻게 높일 것인가?
A :
인코더와 디코더로 구성, 인코더에서는 입력 신퀀스를 벡터로 변환, 디코더는 이를 바탕으로 출력 시퀀스를 생성한다.
이때 어텐션 메커니즘을 활용함
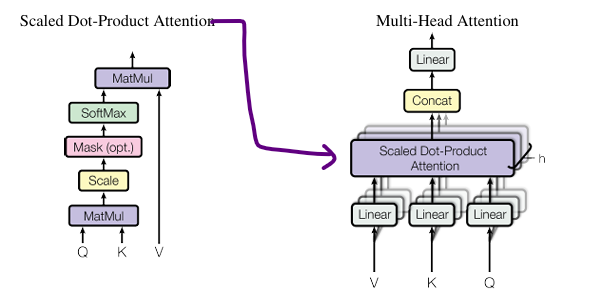
Scaled Dot-Product Attention : 주어진 Query, key, Value 이용 각 단어들 간 상대적 중요도 계산 메커니즘
멀티 헤드 어텐션 : Scaled Dot-Product Attention을 여러 개의 헤드로 분할하여 다양한 관점에서 동시에 학습, 병렬 처리 후 결합, 이를 통해 더 복잡하고 다양한 패턴 포착
Masted 멀티 헤드 어텐션 : 디코더가 현재 위치 에서 다음 토큰을 예측할 때, i 이후 미래 정보 참조 제
모델 내 어텐션 활용:
1. 인코더-디코더 어텐션 :
이전 디코더 레이어에서 나온 Query와 인코더에서 출력된 Key, Value 사용
2. 인코더 셀프 어텐션 :
멀티 헤드 어텐션을 사용하여 입력 문장 속에서 각각의 연관성을 찾는다
3. 디코더 셀프 어텐션:
masked 멀티 헤드 어텐션 사용 이전 위치까지 토큰만 참조하도록 제한
마지막으로 CNN이나 RNN처럼 순서를 알려줄 수 없는 구조임으로 병렬처리 시 순서를 알려주기 위한 Positional Encoding 수
기대효과 :
- 기존 : 입력 시퀀스 길이 에 비례 계산 진행, 시간복잡도 : O(n)
- transformer: 모 든 위치의 단어 표현을 한 번에 병렬적으로 처리, 시간 복잡도 : O(1)
(단, 시퀀스 길이 n이 표현 차원수 d 보다 작은 경우)
(매우 긴 시퀀스 작업 시 반경을 제한하여 해결가능함)
이를 기반으로 이후 BERT, GPT 등에 사용하며 LLM 발전에 막대한 기여를 함
이해한거 정리
transformer 란
이전의 RNN 계열 모델에서 인코더-디코더 구조의 순차적 처리로 인한 병렬처리 한계를 극복하기 위해 생성한 모델이다
이 모델은 이전에도 사용되던 셀프 어텐션 메커니즘을 활용하여 해결하였다.
셀프 어텐션 메커니즘은 Query, Key, Value 각각의 벡터를 만든다. 이 벡터에는 주어진 문맥의 단어나 문장끼리의 Attention Score를 계산하고 이를 가중치로 만드는 메커니즘이다
특히 해당 논문에서는 인코더 디코더를 병렬 구조를 가져갔는데
인코더에서는 주어진 문장을 멀티 헤더 어텐션을 사용하여 다양한 측면으로 문장을 분석하였고, 이를 피드포워드 네트워크를 사용하여 디코더에 전달하였다.
디코더는 이전에 만들어진 벡터에서 현재 스텝의 i 까지만 참고할 수 있도록 제한하는 masked 셀프 어텐션으로 일차 처리한 후 인코더에서 전달받은 값을 활용하여 최종 답변을 생성하도록 하였다.
또한 시퀀스 없이 병렬 처리를 수행함으로 포지셔널 인코딩을 사용하여 모델에 토큰의 순서를 알려주었다.

