https://programmerk.tistory.com/98
LSTM ( long short term memory )
https://programmerk.tistory.com/97 RNNRNN : RNN의 은닉층에 과거 정보를 압축해 저장하는 역할을 하고, 이 정보가 다음 시간 단계로 다시 입력되어 순환되므로 연속된 데이터를 통해 음성, 텍스트, 시계열
programmerk.tistory.com
개념
기존의 입력과 출력을 고정된 차원의 벡터로 표현할 수 있는 제한을 LSTM(Long Short-Term Memory) 구조를 단순하게 적용하여 해결 하는 모델
이전 번역 형태:
규칙 기반 기계번역(Rule-Based Machine Translation, RBMT) :
언어학자가 직접 문법, 구문, 형태소 등 다양한 규칙을 수작업으로 만들어 번역에 적용하는 방식입니다. 장점은 통제된 환경에서 정확한 문법적 번역이 가능하다는 점이고, 문법 규칙이 명확한 언어쌍에 유리합니다. 하지만 규칙을 만들고 유지하는 데 매우 많은 시간과 인력이 필요하며, 새로운 언어나 도메인에 적응하기 어렵다는 단점 => 제약적
통계적 기계번역(Statistical Machine Translation, SMT)
병렬 말뭉치(corpus)를 바탕으로 확률 모델을 학습하여 번역을 수행합니다. SMT는 입력 문장을 토큰 단위(주로 단어나 구)로 나누고, 가장 가능성 높은 번역을 통계적 => 당시 SOTA
**병렬 말뭉치(Parallel Corpus)**란?
사람이 번역한 원문과 번역문이 1:1로 쌍을 이루는 문장 집합입니다. 예를 들어 영어 문장과 그에 대응하는 프랑스어 번역문들이 문장 단위로 정확히 맞춰져 있어야 하며, 이를 통해 두 언어 간의 대응 관계를 학습.
Seq2Seq 구조

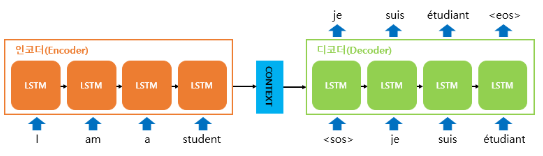
인코더 : 왼쪽 A,B,C 순차 입력 + <EOS> => 입력을 모두 받아 고정 차원 벡터로 변환
디코더 : 인코더로부터 전달받은 벡터를 이용해 W,X,Y,Z + <EOS>
고정 차원 벡터 변환 이유 :
각 단어를 개별적으로 번역한다면, 문맥 정보가 부족해 문장 내 단어간 의미적 연결이 끊길 수 있으며, 결과적으로 번역 문장의 일관성이나 자연스러움이 줄어듭니다. 또한, 문맥이 반영되지 않으면 관용구, 다의어, 문장 구조 등 복잡한 언어적 특성을 제대로 처리하기 어렵습니다.
전체 매커니즘 :
LSTM은 입력 시퀀스를 고정 크기의 벡터 표현 v로 변환하는데, 이 벡터는 LSTM의 마지막 은닉 상태에서 얻는다. 그다음, 이 벡터 를 초기 은닉 상태로 하여 표준 LSTM-LM (Language Model) 수식을 통해 출력 시퀀스에 대한 확률을 계산한다:
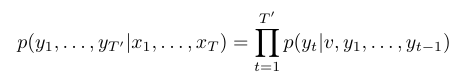
디코더 학습 방법 :
teacher forcing
디코더 학습 시 이전 시점 출력값 대신 실제 정답 시퀀스의 토큰을 다음 시점의 입력으로 강제로 넣어 주는 방법입니다. 이렇게 하면 디코더가 점차 정확한 문맥 정보를 기반으로 학습할 수 있어 누적 오류를 줄이고 학습 안정성을 크게 올립니다. 반면, 테스트(추론)에서는 디코더가 이전 시점의 예측값을 입력으로 사용합니다. 이 차이로 인해 발생하는 학습-추론 불일치 문제(exposure bias)를 해결하기 위해 다양한 개선 기법도 연구되어 왔습니다.

결론 :
결과적으로 WMT’14 영어-프랑스어 번역 작업에서, 5개의 깊은 LSTM 모델(각각 3억 8천만 개의 파라미터)을 앙상블하고 단순한 왼쪽에서 오른쪽으로 진행하는 빔서치 디코더를 사용하여 직접 번역한 결과 BLEU 점수 34.81을 얻었습니다. 이는 대형 신경망을 이용한 직접 번역 중 현재까지 가장 좋은 결과입니다. 참고로, 같은 데이터셋에서 통계적 기계 번역(SMT) 방식의 기준점 BLEU 점수는 33.30입니다. 34.81점은 8만 개 어휘를 가진 LSTM에서 나온 결과라, 기준 번역에 8만 개 어휘에 없는 단어가 포함되면 점수가 깎입니다. 이 결과는 아직 최적화가 덜 된 신경망 모델이 완성도 높은 구문 기반 SMT 시스템보다 더 나은 결과를 낸다는 것을 보여줍니다.
* BLEU : BiLingual Evaluation Understudy의 약자로, 기계 번역의 품질을 자동으로 평가하는 대표적인 지표입니다. 사람이 번역한 참고 문장과 기계가 번역한 문장을 비교하여 얼마나 유사한지 수치로 나타냅니다
* beam search: 한 시점에 가장 가능성 높은 여러 문장 후보(beam)를 유지하며 다음 단어를 확장해서 전체 시퀀스로 가장 높은 확률의 문장을 찾습니다

