[ 정규식 ] - 자바 정규식
업무를보다가 정규식을 사용할 일이 많았지만 항상 검색해서 코드만 가져다 쓸 뿐 이렇게 직접 작성은 처음해보는것같다. 개인공부를 하면서 코테 공부도 해보려고 코테에 관련있는 분야부터 시작하게되었다.
일단 기본 문법부터 찾아봤다
^ : 시작을 강제해준다. ex) ^(010) : 010으로 시작해야함
& : 종료를 강제해준다 ex) (com)& : com으로 끝나야함
. : 하나의 문자가 있으면된다 (띄어쓰기 포함 )
[ ] : 특정 문자 포함하는지 체크 ex) [12] : 12345678 중 12를 체크함
[A-Z] : - 가 들어가면 범위를 정할수 있다. ex) [0-9] : 0~9까지 숫자 하나 들어있으면됨
[13] : 1 or 3 을 체크한다.
[^1] : 괄호 안에서 ^ 은 not을 의미한다 ,
\s : 띄어쓰기 , \t , \n 을 체크한다
\S : \s에 해당되는것을 제외한 나머지를 체크
( ) : 문자열을 포함한다 ex) (010) : 010 있는지 체크
(a|b) : a or b 체크
+ : 1회 이상 반복을 의미
* : 0회 이상 반복을 의미 + 냐 * 이냐 에따라 결과가 달라질수있다.
? : 있을수도있고 없을수도있다.
{} : 조건에 일치하는 자리수를 체크한다
(?=) : 전방탐색 , 맨앞부터 검사를 하며 = 다음에오는 일치하는 양식을 조건에서 제외한다 (?=[0-9]{4}) ex) 핸드폰번호 뒷자리 찾을때
(?<=) : 후방탐색 , 뒤부터 검사하여 = 다음에오는 일치하는 약식을 조건에서 제외한다 (?<=[0-9]{3}) ex) 핸드폰번호 앞자리 찾을때
==================== 추가
(?:aa) : aa 가 들어갈수도있고 다른게 들어갈수도있지만 aa형태를 1번이상 가지고있는것을 찾는다

(?i) : 대소문자 무시
\b : 문자와 공백 사이 의미하며 , 아래 예시처럼 앞뒤로 감싸고있으면 특정 word와 정확하게 일치해야만 찾음

만약 아래 처럼 뒤에 \b를 삭제하면 정확하게 일치하지않아도 해당 문자를 찾기는함

테스트 코드
String result = "The cat sat on the mat.12#";
System.out.println(result.replaceAll("[Tt]he", "*")); // T or t 이고 뒤에 he 인 모든 텍스트 치환 * The,the
System.out.println(result.replaceAll("[T]he","*")); // T 이고 뒤는 he인 첫 텍스트 치환 * The
System.out.println(result.replaceAll("\\s", "*")); //\t \n \x0b \r \f 를 * 치환
System.out.println(result.replaceAll("\\S","*")); //\t \n \x0b \r \f 를 제외한 문자 * 치환
System.out.println(result.replaceAll("\\b", "*")); // 단어 경계 찾아 치환
System.out.println(result.replaceAll("[1]", "*")); // 문자중 1 있는경우 일치하는것만 치환
System.out.println(result.replaceAll("[12]", "*")); // 문자중 1 or 2 or 12 일치하는것만 치환
System.out.println(result.replaceAll("[13]", "*")); // 문자중 1 or 3 or 13 일치하는것만 치환
System.out.println(result.replaceAll("[1-3]", "*")); // 문자중 1 or 2 or 3 일치한느것 치환
System.out.println(result.replaceAll("[^1]", "*")); // 문자중 1을 제외한 모든 문자 치환
System.out.println(result.replaceAll("[^1-3]", "*")); // 문자중 1 or 2 or 3 제외한 모든 문자 치환
System.out.println(result.replaceAll("(The|the)", "*")); // The or the 이면 치환
System.out.println(result.replaceAll("(on)+", "*")); // on 이 1번이상 반복되면 치환
System.out.println(result.replaceAll("(on)*", "*")); // on 이 0번이상 반복되면 치환
System.out.println(result.replaceAll("[2]$", "*")); // 맨마지막문자가 2라서 치환 안됨
System.out.println(result.replaceAll("[#]$", "*")); // 맨 마지막 문자가 # 이면 치환
System.out.println(result.replaceAll("1#$", "*")); // 맨 마지막 문자가 1# 이라서 치환 안됨
System.out.println(result.replaceAll("2#$", "*")); // 맨 마지막 문자가 2# 이면 치환
결과

URL 체크 코드
String[] inputs = {"www.naver.com", "http://naver.com","https://naver.com","http://www.naver.com","naver.com/web","naver.com/web/","naver"};
String reg = "^((http|https)://)?(www.)?[a-zA-Z0-9]+\\.[a-zA-Z]+(/[a-zA-Z0-9]*)?[^/]";
//String reg = "^((http|https)://)?(www.)?[a-zA-Z0-9]+.[a-zA-Z]+(/[a-zA-Z0-9]*)?[^/]";
for(String input: inputs) {
if(Pattern.matches(reg, input)) {
System.out.println("urlCheck : "+input +" = "+true);
}else {
System.out.println("urlCheck : "+input +" = "+false);
}
}
^((http|https)://)?(www.)?[a-zA-Z0-9]+.[a-zA-Z]+(/[a-zA-Z0-9]*)?[^/] 을 하나하나 말로 풀어보자
^: 맨앞이
(http|https)://)? : http 이거나 https 이고 :// 을 일수도있고 아닐수도있다
(www.)? : 위에 문장이거나 www. 일수도있고 아닐수도있다
이 문장을통해 앞에올수있는 문자는 아무문자가 안오거나 , http:// or https:// or www. 네가지종류이다
[a-zA-Z0-9]+. : 영소,영대,숫자가 1번이상 반복해야한다, 마지막은 . 이다
[a-zA-Z] : 영소,영대,1번이상 반복해야한다,
(/[a-zA-Z0-9]*)? : / 와 함께 영소,영대,숫자가 1번이상 반복할수도있고 안할 수도있다.
[^/] : 마지막은 / 가 올수없다.
1."^((http|https)://)?(www.)?[a-zA-Z0-9]+.[a-zA-Z]+(/[a-zA-Z0-9]*)?[^/]";
2."^((http|https)://)?(www.)?[a-zA-Z0-9]+\\.[a-zA-Z]+(/[a-zA-Z0-9]*)?[^/]";
1번과 2번에 따라 마지막 결과가 다르게 나온다
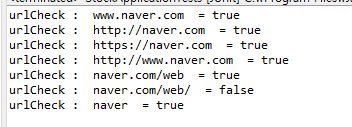

.에 의미를 알아보기 다시 테스트
@Test
void dotCheck() {
String[] inputs = {".","a.",".b",".."};
String reg = "\\..";
for(String input: inputs) {
if(Pattern.matches(reg, input)) {
System.out.println("dotCheck : "+input +" = "+true);
}else {
System.out.println("dotCheck : "+input +" = "+false);
}
}
}

결과를 보니 \\. : 텍스트 . 의미하고 뒤에 . 는 정규식에서 사용하는 . 으로 아무문자나 올수잇는 판단된다.
그러므로 1번의 + 와 . 이 합쳐저서 naver 라는 텍스트가 정상으로 판단하고
2번은 \\. 이 텍스트 .을 의미해서 false 로 처리한것으로 생각된다.
이메일 주소 체크 코드
@Test
public void emailCheck() {
String[] inputs = {"kkkk@ai.com", "kkkk@naver.com","kkk@naver.com"
,"k1k1kk1k1k1k1k1@naver.com","k123.com","kadmin@kadmin@naver.com"};
String reg="";
for(String input: inputs) {
if(Pattern.matches(reg, input)) {
System.out.println("emailCheck : "+input +" = "+true);
}else {
System.out.println("emailCheck : "+input +" = "+false);
}
}
}
^[a-zA-Z0-9]{4,10}@[a-zA-Z0-9]{5,10}\\.[a-zA-Z]+ 을 해석해보면
// ^ ==> 시작 표시
// [a-zA-Z0-9]{4,10} 영소,영대,숫자 인 텍스트가 4~10자리 이여야한다 \\w 로 대체가능
// @ ==> "@" 텍스트 포함
// [a-zA-Z0-9]{5,10} 영소,영대,숫자 인 텍스트가 4~10자리 이여야한다 \\w 로 대체가능
// \\. ==> "." 텍스트 포함
//[a-zA-Z]+ 영소,영대 문자가 1회이상 반복되야한다

휴대전화 번호 체크 코드
@Test
public void phoneCheck() {
String[] inputs = {"01012345678", "0111234-5678","016-1234-5678"
,"017-123-4567","019-123-456","010-12-4567"};
String reg = "^(010|011|016|017|019)-[0-9]{3,4}-[0-9]{4}";
//String reg1 = "^0(0|1)(0|1|6|7|9)-[0-9]{3,4}-[0-9]{4}";
for(String input: inputs) {
if(Pattern.matches(reg, input)) {
System.out.println("phoneCheck : "+input +" = "+true);
}else {
System.out.println("phoneCheck : "+input +" = "+false);
}
}
}
^(010|011|016|017|019)-[0-9]{3,4}-[0-9]{4} 해석해보면
^(010|011|016|017|019) : 폰의 앞자리는 010,011,016,017,019 , 그리고 3자리 이다
- : 첫번째 자리와 두번째 자리 사이에 - 붙는다
[0-9]{3,4} : 두번째자리는 숫자로만되고 3~4 글자 이다
- : 두번째 자리와 세번째 자리 사이에 - 붙는다
[0-9]{4} : 세번째 자리는 수자로만 되고 4 글자 이다

특정 문자 * 처리
일하다보면 개인정보 때문에 특정 문자를 * 치환할 일이 발생한다.
1. 번호 마지막 4자리 제외 * 처리
@Test
public void regMethod() {
String[] inputs = {"01012345678", "0101234567","010-1234-5678","010-123-4567"};
for(String input: inputs) {
if(input.indexOf("-")==-1) {
String reg=".(?=[0-9]{4})";
System.out.println("regMethod : "+input.replaceAll(reg, "*"));
}else {
String reg=".(?=[0-9\\-]{4})";
System.out.println("regMethod : "+input.replaceAll(reg, "^"));
}
}
}

2. 이메일 주소 2번째 3번째 문자 * 처리
원래는 정규식만써서 해보고싶엇는데.. 포기 ......
처리순서는
1. 띄어쓰기 제거
2. @를 포함하는 문자있는지 체크
3. string to char[]
4. char[2]과 char[3] 값이 [a-z0-9] 포함될때 * 로 치환 후 string에 붙인다.
5. 4번에 해당안될경우 치환안하고 그냥 붙는다
@Test
public void regMethod2() {
String[] inputs = {"kkk k@ai.com", "kkk k@naver.com","k kk@naver.com"
,"k1k1kk1 k1k1k1k1@naver.com","k123.com","kadmin@kadmin@naver.com"};
for(String input: inputs) {
input=input.replaceAll("\s", "");
String reg = ".*\\@.*";
if(Pattern.matches(reg, input)) {
reg = "[a-z0-9]";
char [] cArray = input.toCharArray();
input="";
for(int i=0;i< cArray.length;i++) {
if(i==2|| i==3) {
input+=Character.toString(cArray[i]).replaceAll(reg,"*");
}else {
input+=Character.toString(cArray[i]);
}
}
System.out.println("regMethod2 : "+input);
}
}
}